
- Joined
- Sep 3, 2014
- Messages
- 6,329
- Likes
- 13,318
- Degree
- 9

Technical SEO is the foundation of search engine optimization. I don't mean it is the most basic or easy to grasp concept. I mean that everything builds off of this groundwork.
There's no expectation to get it 100% right. But getting it wrong can spell doom for your site, literally. You can end up with, on the lightest end, a reduced SERP exposure and an algorithmic penalty. On the heaviest end you could end up de-indexed.
Here's an example of getting something seemingly minor wrong and what happens when you fix it. This is one of my own sites:
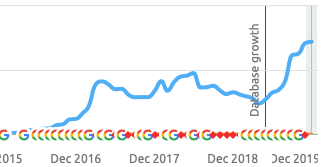
I'd wager most people don't even realize Technical SEO exists, and most of those that do ignore it because they figure Wordpress has it sorted out. Then they install a random theme that hurts them, then they compound the issue with plugins. Then they get confident and mess with their robots.txt and .htaccess files. And since this is already sorted out for them, they never watch their Search Console Coverage Reports that are spitting errors out left and right as their indexation tanks and their impressions and clicks begin to suffer.
That's enough fear mongering for today. It's not an exaggeration, but let's get on to the education side of things...
What is Technical SEO?
Tech SEO revolves around how you control two critical aspects of how a search engine works:
- Crawling
- Indexing
Crawling - This refers to how the search engine's "spiders" (bots that crawl along the web) move throughout your website. Where do they go? What can they see or not? Discoverability is the phrase to remember.
Indexing - Spiders will find everything possible and take note of it to be included in the search results. This means the page is free to appear in the index. That is the process of indexing. But should everything be indexed? What about things that should but aren't?
These are the two main items we are concerned with. Everything else is a sub-set of these two things, and usually both at the same time.
Let's cover both of these in order in greater depth, which will include tasks and problems you will want to consider as you audit your website. That is a term you'll hear tossed around: "auditing your website." This is the act of trying to analyze how spiders crawl your site, what is indexed or not, looking at server logs, etc... in an act to improve crawling & indexing.
We'll start by doing a quick and very basic overview of the process, dealing only with discoverability and indexing. It's better for you to see the entire process, even if it's super limited, than to get lost in the details for now.
Crawling - Hide & Seek
Maybe you haven't stopped to think how a search engine like Google finds your site and then discovers everything about it. Google drops its spiders out onto the web in various places, like a seed set of authority sites, RSS feed aggregators, ping sites, recent domain registry lists, etc. Then those spiders go out and multiply. If they hit a page with 10 links, they'll spawn off 9 more spiders to follow all the links. They want to discover everything and have become exceedingly good at it.
Guess what? You can do the same thing. The main tool in your SEO Audit arsenal is a crawler, which is a software that sets loose spiders wherever you tell it and then crawls based on the parameters you set for it. Some examples are:
These will put you in control of the spiders and give varying amounts of data at different prices (including free). There's the typical SaaS's that now offer crawls too, like Ahrefs, Moz, Sitebulb, SEMRush, etc. These will also try to unearth any problems you might have. But if you don't know what to watch out for, you should probably not use these shortcuts and instead keep reading this guide.
Using a crawler is the fastest and easiest (and only sane) way of getting the data you need to fix any problems on your site.
"Hops" during a crawl (leaps to the next page or file) don't only occur using hyperlinks. They occur through embedded absolute URLs (https://...) in the source code and relative URLS (.../picture.jpg). If a link can be found, it will be crawled (unless you direct the spider otherwise, which we cover later).
Typically you'd have varying goals per crawl instead of trying to do everything in one shot. The first and main thing I'd try to uncover is how efficiently I'm using my "crawl budget."
Crawl Budget
A crawl budget refers to how much resources Google will allocate for crawling your website at any given time. Google assigns every website a crawl budget. They say small sites don't need to worry about it. But there's also the case that there seems to be a correlation between crawl frequency and crawl depths and positive rankings. So just because you don't "need to worry about it" doesn't mean you shouldn't.
Big sites and eCommerce sites definitely need to worry about this. There's a million ways you can goof this up, like sending spiders into infinite loops, endless dofollow & noindex hops, and through countless amounts of duplicate content like in faceted navigation on an eCommerce store. If this problem exists long enough, Google will reduce your crawl budget, rather than waste a ton of time in your funhouse hall of mirrors.
Small sites can't skip this, though. What happens when spiders unearth large portions of your admin area or start digging through your folder hierarchy and exposing that to the masses in the index?
Your first order of action is to use one of the crawlers above, tell it to ignore external links and images, and set it loose on your site starting at the homepage. Just see what it turns up and make sure it's only what you expect and nothing more. Remember, for this short example we're only worrying about discoverabliity.
Indexing - Sought & Found
Google's spider's job is to crawl your site, use it to find other sites, and index everything they're allowed to index. When you ran your crawl on your own site, your objective is to determine two things:
- What is discoverable on my site?
- What is indexable on my site?
Second, what you want to do is compare the amount of unique URLs being found on your crawl against what Google is actually indexing. The old way to find out how much of your site Google indexed was to use the
site:domain.com search operator and compare that number to what was reported in the old, inaccurate Webmaster Tools. Now that it's Search Console v2.0 with the Coverage Report, you can just look at that, which is perfectly accurate.Real Life Example
Here's a real life example that happened to me. I created an affiliate link system using PHP redirects and text files. I could build a link like this:
domain.com/walmart/automotive/product-name. So in this made-up case, I have a folder at the root of my site called walmart that contains various folders with one called automotive. All of these folders contained .htaccess files to make sure they're all set to noindex.Inside the
automotive folder, there is the .htaccess file and a .txt file. The text files contains lines like this: product-name,https://walmart.com/product-name?aff=myID. This level of folders also contain a PHP file that creates a redirect. It scans the text file for product-name, matches the start of the line, and redirects to the URL after the comma.So note, all of these folders are noindex and 302 redirect to the homepage. The correct product 302 redirects to the product page at the respective store. Also, each redirection tosses up HTTP headers that reiterate the noindex directive and also throw up a nofollow for all links in the redirect.
So what's the problem? None of the folders or redirections should get indexed and should all be nofollow.
Two things happened:
- Turns out, the nofollow HTTP header directive only applies to links on the page. Since there are no links on the page (because there is no page, only a redirection) these ended up being dofollow links. So now I have "incentivized links" on my site (aka paid links).
- At some point I said "why even let Google crawl these folders" and used the robots.txt to block crawling to anything in the
/walmart/folder.
Note that my site had about 300 pages of real content and now had an additional 800 blank pages indexed. Guess what happened? PANDA. My site quality score went down and down, because Panda analyzes the cumulative quality of only what's in the index. And I had an 8:3 ratio of literally "nothing" pages indexed to every 3 good pages. This is why indexation matters.
It took me around 6 months to get that crap out of the index once I removed the robots.txt disallow directive to that folder. Even with tricks like adding sitemaps with just those links, it took forever.
#1 ended up being an issue, because fortuitously at the time John Mueller came out and said the "nofollow HTTP header" only applies to links on the page. If it's a redirect, there are no links, thus the HTTP header is ignored. This meant I had to go through my entire site and add nofollow
rel tags to all these hyperlinks... manually. I didn't have them before because the HTTP header should have overridden it.So not only did I have a bunch of junk indexed because Google could NOT crawl the affiliate link folder, which meant they could NOT see the noindex directive in the HTTP header, I also was wasting my crawl budget once they were allowed to crawl because the links weren't explicitly nofollow'd on the page.
Panda is supposedly now the Panda Everflux, running every 30 days. That may be true, but do you really think they're refreshing the Panda data every 30 days? I think not. If you tank your site like this, you have to find the problem, fix it, and wait while your income takes a hit until you get a true Panda refresh.
This is why crawling & indexing matter.
Additional Reading:
Last edited:


